

NI Compuτe: Subnet Miner Setup
How to Mine on the Bittensor NI Compute Subnet (SN27) - The Permission-less Compute Market
1. INTRODUCTION
For miners interested in joining this innovative network, Subnet 27 offers the opportunity to contribute computing resources and earn $NI in return. This guide is structured to provide a comprehensive breakdown of how you can get started with contributing to Bittensor’s commodity markets using your compute power.
Decentralizing Compute
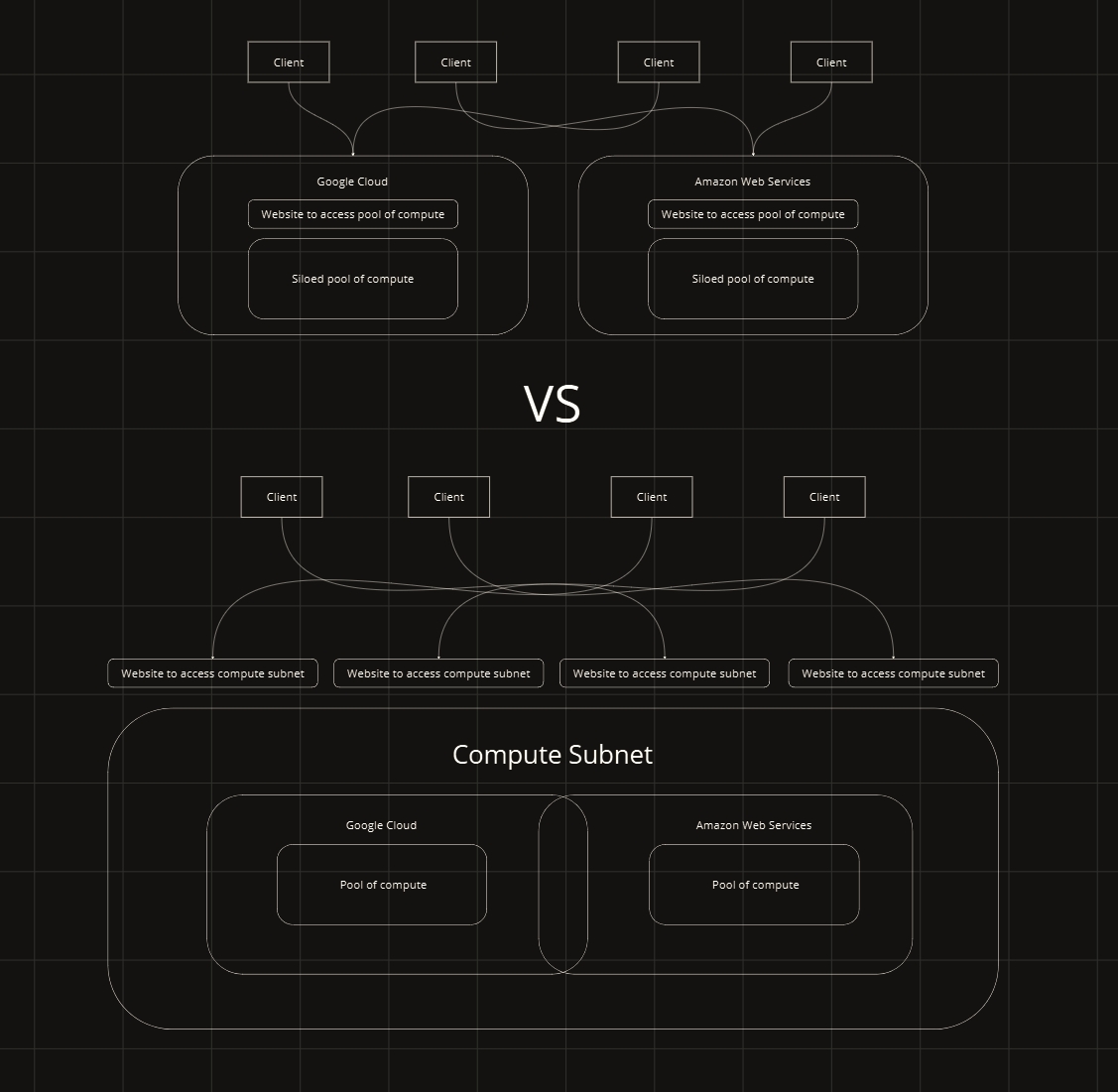
NI Compute decentralizes computing resources by combining siloed pools of compute on a blockchain to be validated and accessed trustlessly. This opens a door to scalable compute without the constraints of centralized power.
Powered By Bittensor
NI Compute brings, arguably, the most important and finite resource needed for the creation of machine intelligence. All network participants will have access to an ever-expanding pool of compute for all development needs.
What is a decentralized supercomputer without access to permissionless compute?

Miner Overview:
Miners contribute processing resources, notably GPU (Graphics Processing Unit) instances.
Performance-Based Mining: The system operates on a performance-based reward mechanism, where miners are incentivized through a dynamic reward structure correlated to the processing capability of their hardware. High-performance devices are eligible for increased compensation, reflecting their greater contribution to the network's computational throughput. Emphasizing the integration of GPU instances is critical due to their superior computational power, particularly in tasks regarding machine learning.

Rent A Server From Subnet 27: https://app.neuralinternet.ai/
Compute Subnet Github: https://github.com/neuralinternet/compute-subnet
Compute Subnet Discord Channel: https://discord.gg/t7BMee4w
Real-Time Compute Subnet Metrics: https://opencompute.streamlit.app/
We greatly appreciate and encourage contributions from the community to help improve and advance the development of the Compute Subnet. We have an active bounty program in place to incentivize and reward valuable contributions.
If you are interested in contributing to the Compute Subnet, please review our Reward Program for Valuable Contributions document on GitHub. This document outlines the details of the bounty program, including the types of contributions eligible for rewards and the reward structure.
Reward Program for Valuable Contributions: https://github.com/neuralinternet/compute-subnet/blob/main/CONTRIBUTING.md
Validator CLI Guide For Reserving Compute Subnet Resources: Validator Utilization of Compute Resources
Example Cloud Providers:
We do not support Containerized (docker)-based cloud platforms such as Runpod, VastAI and Lambda.
We strongly urge miners to provide their own hardware to foster and build a stronger network for all. Providing your own in-house hardware may come with its own benefits.
If you cannot supply your hardware in-house, here are some usable GPU providers:
Latitude.sh (referral code: BITTENSOR27)
Oblivus (referral code: BITTENSOR27 - 2% cash back in platform expenditures)
Examples of GPUs to rent (listed in order of computing power):
GPU Base Scores: The following GPUs are assigned specific base scores, reflecting their relative performance. To understand scoring please see the Proof-of-GPU page here:
NVIDIA H200: 4.00
NVIDIA H100 80GB HBM3: 3.30
NVIDIA H100 80GB PCIE: 2.80
NVIDIA A100-SXM4-80GB: 1.90
2. INSTALLATION
Install Docker
Install Link: https://docs.docker.com/engine/install/ubuntu/#install-using-the-repository
Verify that the Docker Engine installation is successful by running the hello-world image.
sudo docker run hello-world2.1 BEGIN BY INSTALLING BITTENSOR:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/opentensor/bittensor/master/scripts/install.sh)"See Bittensor’s documentation for alternative installation instructions.
Bittensor Documentation: docs.bittensor.com
2.2 VERIFY THE INSTALLATION:
Verify using the btcli command
btcli --helpwhich will give you an output similar to below:
usage: btcli <command> <command args>
bittensor cli v6.9.4
positional arguments:
{subnets,s,subnet,root,r,roots,wallet,w,wallets,stake,st,stakes,sudo,su,sudos,legacy,l,info,i}
subnets (s, subnet)
Commands for managing and viewing subnetworks.
root (r, roots) Commands for managing and viewing the root network.
wallet (w, wallets)
Commands for managing and viewing wallets.
stake (st, stakes) Commands for staking and removing stake from hotkey accounts.
sudo (su, sudos) Commands for subnet management
legacy (l) Miscellaneous commands.
info (i) Instructions for enabling autocompletion for the CLI.
options:
-h, --help show this help message and exit
--print-completion {bash,zsh,tcsh}
Print shell tab completion scriptCreate a Cold & Hotkey with the commands below:
btcli w new_coldkeybtcli w new_hotkeybtcli w regen_coldkeypubbtcli w regen_coldkeybtcli w regen_hotkey4. CLONE COMPUTE-SUBNET
git clone https://github.com/neuralinternet/Compute-Subnet.gitAccess the Compute-Subnet Directory
cd Compute-Subnet5. COMPUTE SUBNET DEPENDENCIES
Required dependencies for validators and miners:
python3 -m pip install -r requirements.txt
python3 -m pip install --no-deps -r requirements-compute.txt
python3 -m pip install -e .5.1 EXTRA DEPENDENCIES FOR MINERS:
In case you have missing requirements
sudo apt -y install ocl-icd-libopencl1 pocl-opencl-icdDownload the NVIDIA CUDA Toolkit
To ensure optimal performance and compatibility, it is strongly recommended to install the latest available CUDA version from NVIDIA.
If Nvidia toolkit and drivers are already installed on your machine, scroll down to verify then move on to the Wandb Setup.
# Visit NVIDIA's official CUDA download page to get the latest version:
# https://developer.nvidia.com/cuda-downloads
# Select your operating system, architecture, distribution, and version to get the appropriate installer.
# Example for Ubuntu 22.04 (replace with the latest version as needed):
# Download the CUDA repository package (update the URL to the latest version)
wget https://developer.download.nvidia.com/compute/cuda/12.3.1/local_installers/cuda-repo-ubuntu2204-12-3-local_12.3.1-545.23.08-1_amd64.debsudo dpkg -i cuda-repo-ubuntu2204-12-3-local_12.3.1-545.23.08-1_amd64.debsudo cp /var/cuda-repo-ubuntu2204-12-3-local/cuda-*-keyring.gpg /usr/share/keyrings/sudo apt-get updatesudo apt-get -y install cuda-toolkit-12-3sudo apt-get -y install -y cuda-driversexport CUDA_VERSION=cuda-12.3
export PATH=$PATH:/usr/local/$CUDA_VERSION/bin
export LD_LIBRARY_PATH=/usr/local/$CUDA_VERSION/lib64echo "">>~/.bashrc
echo "PATH=$PATH">>~/.bashrc
echo "LD_LIBRARY_PATH=$LD_LIBRARY_PATH">>~/.bashrcsource ~/.bashrcYou may need to reboot the machine at this point to finalize changes
sudo rebootThe simplest way to check the installed CUDA version is by using the NVIDIA CUDA Compiler (nvcc).
nvidia-smi
nvcc --versionThe output of which should look something like
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.29.06 Driver Version: 545.29.06 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA RTX Off | 00000000:05:00.0 Off | Off |
| 30% 34C P0 70W / 300W | 400MiB / 4914000MiB | 4% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Fri_Nov__3_17:16:49_PDT_2023
Cuda compilation tools, release 12.3, V12.3.103
Build cuda_12.3.r12.3/compiler.33492891_0Wandb Setup
To log into the wandb project named opencompute from neuralinternet, miners and validators need a wandb API key. This is necessary for your miner to be properly scored. You can obtain a free API key by making an account here: https://wandb.ai/
Inside of the Compute-Subnet directory; Rename the .env.example file to .env and replace the placeholder with your actual API key.
You can now track your mining and validation statistics on Wandb. For access, visit: https://wandb.ai/neuralinternet/opencompute. To view the networks overall statistics check out our real-time dashboard here: https://opencompute.streamlit.app/
PM2 Installation
Install and run pm2 commands to keep your miner online at all times.
sudo apt updatesudo apt install npmsudo npm install pm2 -gConfirm pm2 is installed and running correctly
pm2 ls5.2 INSTALL NVIDIA DOCKER SUPPORT
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.listsudo apt updatesudo apt-get install -y nvidia-container-toolkitsudo apt install -y nvidia-docker26. START THE DOCKER SERVICE IN COMPUTE SUBNET
cd Compute-Subnetsudo groupadd dockersudo usermod -aG docker $USERsudo systemctl start dockersudo apt install atMake sure to check that docker is properly installed and running correctly:
sudo service docker statusThis is an example of it running correctly:
root@merciful-bored-zephyr-fin-01:~# sudo service docker status
● docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset>
Active: active (running)7.0 SETTING UP A MINER
Hotkey Registration
At this point, you will need some $TAO in your coldkey address for miner registration. Once your coldkey is funded, run the command below to register your hotkey:
btcli s register --subtensor.network finney --netuid 277.1 SETTING UP UFW FOR MINER:
Open your desired ssh port for allocations; default is 4444 (required for allocation):
sudo apt updatesudo apt install ufwsudo ufw allow 4444sudo ufw allow xxxx:yyyy/tcpsudo ufw allow 22/tcpsudo ufw enablesudo ufw status7.2 RUNNING THE MINER:
Miner options
--miner.whitelist.not.enough.stake: (Optional) Whitelist the validators without enough stake. Default: False.--miner.whitelist.not.updated: (Optional) Whitelist validators not using the last version of the code. Default: False.--miner.whitelist.updated.threshold: (Optional) Total quorum before starting the whitelist. Default: 60. (%)
Now, using pm2, run miner as:
pm2 start ./neurons/miner.py --name MINER --interpreter python3 -- --netuid 27 --subtensor.network finney --wallet.name COLDKEYNAME --wallet.hotkey HOTKEYNAME --axon.port XXXX --axon.ip xx.xxx.xxx.xx --logging.debugSubVortex subtensor (recommended):
pm2 start ./neurons/miner.py --name MINER --interpreter python3 -- --netuid 27 --subtensor.network subvortex.info:9944 --wallet.name COLDKEYNAME --wallet.hotkey HOTKEYNAME --axon.port xxxx --logging.debug8. CHECKING MINER LOGS
After launching the compute miner, you can then check the logs using the two commands below:
pm2 logspm2 monit



10. MORE USEFUL COMMANDS
btcli s metagraph --netuid 27btcli s listbtcli wallet overview --subtensor.network finney --all --netuid 27pm2 logs miner --lines 1000 | grep -i "Challenge.*found"pm2 logs -f | grep -E "SUCCESS|INFO|DEBUG|ERROR"nvidia-smi --query-gpu=name,memory.total,clocks.gr,clocks.mem --format=csvgrep "Challenge .* found in" "/home/ubuntu/.pm2/logs/MINER-out.log" | sed -E 's/.* found in ([0-9.]+) seconds.*/\\1/' | awk '{sum+=$1; count+=1} END {if (count > 0) print sum/count; else print "No data to calculate average"}’btcli w transfer --subtensor.network local --dest DESTINATION_WALLET --wallet.name default --amount 0btcli stake remove --subtensor.network local --all --all_hotkeys --wallet.name defaultLast updated